How you feelin’? Learning Emotions and Mental States in Movie Scenes
Katha-AI Lab, IIIT-Hyderabad
CVPR 2023
CVPR 2023

Abstract
Automatic movie analysis is incomplete if characters’ emotions and mental states are not perceived. We formulate emotion understanding for a movie scene as predicting a diverse and multi-label set of scene and per character emotions. Addressing this challenging problem requires multimodal models. We propose EmoTx, a Transformer-based architecture that ingests video frames, multiple characters, and dialog utterances to jointly predict scene and character-level emotions. We conduct experiments on the most frequently occurring 10 or 25 labels, and a mapping that clusters 181 labels to 26 emotions. Ablation studies show the effectiveness of our design choices. We also adapt popular (multimodal) emotion recognition approaches for our task and show that EmoTx outperforms them all. Furthermore, analyzing self-attention scores reveals EmoTx’s ability to identify relevant modalities across a long video clip and verifies that mental states rely on video and dialog, while expressive emotions look at character tokens.
Motivation





Paper

@inproceedings{dhruv2023emotx,
title = {{How you feelin'? Learning Emotions and Mental States in Movie Scenes}},
author = {Dhruv Srivastava and Aditya Kumar Singh and Makarand Tapaswi},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}
EmoTx Model
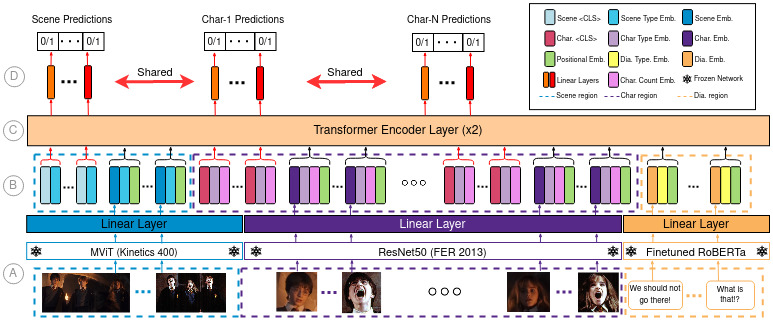
An overview of EmoTx. A: Given sequential video frame features (in blue region), character face features (in purple region), and utterance features (in orange region) extracted using respective pretrained models, the modality specific linear layers project the inputs into a joint embedding space. B: Here appropriate embeddings are added to the tokens to distinguish between modalities, character indices, and to provide a sense of time. We also create per-emotion classifier tokens associated with the scene or a specific character. C: Two Transformer encoder layers perform self-attention across the sequence of input tokens. D: Finally, we tap the classifier tokens to produce output probability scores for each emotion through a linear classifier shared across the scene and characters.
Sample predictions from test set videos
Char predictions: [(Jenny, (angry, shocked, sad, scared, determined, alarmed)), (Forrest Gump, (shocked, scared, alarmed))]
Char predictions: [(Detective, (shocked, scared, alarmed)), (Hendricks, (angry, shocked, scared, upset, alarmed)), (Dale, (scared)), (Kurt, (scared))]
Char predictions: [(Pete, (sad)), (Debbie, (sad, upset))]
Char predictions: [(Ron, (curious)), (Eve, (happy))]
Char predictions: [(Nick, (scared)), (Kurt, (scared)), (Dale, (scared, quiet)), (Jones, (quiet))]
Char predictions: [(Brent, (shocked)), (Alison, (sad, upset, confused))]
Char predictions: [(Walter, (angry, shocked, alarmed)), (Donny, (angry, shocked)), (Dude, (angry, shocked, upset))]
Char predictions: [(Nick, (quiet, scared)), (Dale, (shocked)), (Kurt, (quiet, scared)), (Wetwork man, No Pred.)]
Qualitative Analysis
EmoTx provides an intuitive way to understand which modalities are used to make predictions. We refer to the self-attention scores matrix as α, and analyze specific rows and columns. Separating the K classifier tokens allows us to find attention-score based evidence for each predicted emotion by looking at specific rows in the attention matrix.
Analysis 1
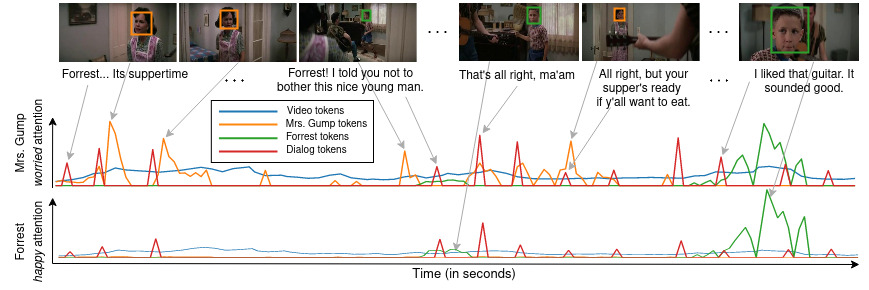
A scene from the movie Forrest Gump showing the multimodal self-attention scores for the two predictions: Mrs. Gump is worried and Forrest is happy. We observe that the worried classifier token attends to Mrs. Gump’s character tokens when she appears at the start of the scene, while Forrest’s happy classifier token attends to Forrest towards the end of the scene. The video frames have relatively similar attention scores while dialog helps with emotional utterances such as told you not to bother or it sounded good.
Analysis 2
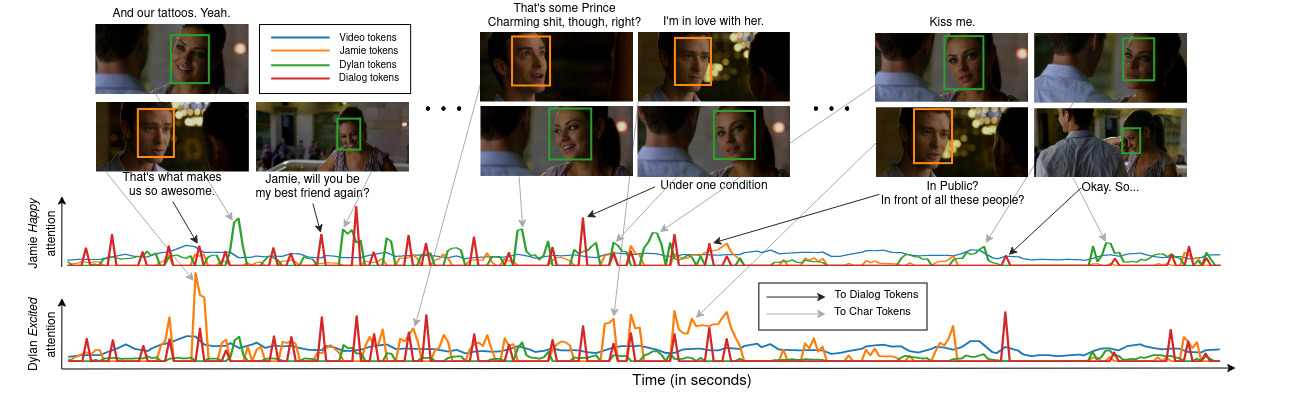
A scene from the movie Friends with Benefits with self-attention scores for multiple modalities for two character-level predictions: Jamie is happy and Dylan is excited. From the figure we can infer that the happy classifier token attends to the Jamie character tokens with spikes observed when she smiles or laughs, while Dylan’s excited classifier token attends primarily to the dialog utterance tokens. We can see this as very few face snaps indicate that Dylan is excited, in fact, Dylan’s face is not even visible often. However, dialog utterances like That’s what makes us so awesome, Hey, I miss you, and Jamie, will you be my best friend again? are extremely useful for the model to infer the emotions.
For qualitative analysis on Expressive v/s Inexpressive emotions and other cool stuff, refer the full text pdf!